
PostgreSQL Is Having a Moment
34 SQL migrations in 5 weeks, painless. Six years ago I'd have picked NoSQL — and would have been right. Agents flipped the tradeoff.
I shipped the first release of Oval Brief in 5 weeks of part-time work. In that span, I ran 34 SQL migrations against the production schema — adding columns, splitting columns, extracting tables from a JSONB column, swapping indexes, and flipping constraints. With the help of AI coding agents, it was painless and had zero negative impact on velocity.
Six years ago at ZeroBase, I made the opposite architectural choice, and I don’t think I was wrong then. The tradeoff has flipped, plain and simple. The calculus has changed because of agentic development.
The NoSQL choice that made sense
ZeroBase was a financial planning SaaS built to replace Excel. When a user edited a number in the income statement, they expected the change to ripple up the hierarchy instantly — parent rollups, annual totals, every downstream view updating without a refresh.
The data model was a tree of Firestore documents: one per account, linked by parent-child relationships. When you wrote a new value, a Cloud Function computed the delta and pushed it up the tree. What you got back was real-time sync across every client subscribed to the affected documents. Backfill, reconnection, ordering guarantees, and a web-socket-replacement channel baked into the SDK. We didn’t have to build any of it.
Replicating that on Postgres in 2020 would have meant standing up our own real-time pipeline. Postgres LISTEN/NOTIFY wired up to a WebSocket layer, or logical decoding into a Redis pub/sub fan-out, or just long-polling with cache invalidation — and then handling reconnection and backfill ourselves. A week of work on a good day. A month when the edge cases started showing up.
So we picked Firestore, and it was the right call.
The secondary draw, more interesting in retrospect, was that the data model was still moving. We didn’t know what fields a “labor account” would need three months in. Firestore let us evolve the shape as we went, without the mental distractions and risks of migrations gone wrong.
This looks entirely different in 2026.
The hidden cost: schema drift as a class of problem
The pattern, in Firestore-world, goes like this.
You realize you need a new field on an existing document type. You add it in the code that writes new documents. You mark it optional in TypeScript because old documents don’t have it. You update the read sites you can remember. Life goes on.
Two weeks later, a function three levels deep in the rollup calculation reads one of those old documents, doesn’t find the field, and returns undefined where it expected a number. The income statement quietly shows zeros in one branch.
The fix is never hard. It’s a missing ?? 0 somewhere, or a one-off script that backfills the field. The problem is that you can’t see the fix coming because the schema isn’t a contract. It’s a convention held together by TypeScript optionals and whoever last remembered what documents actually look like.
The cost shows up slowly, everywhere. Excessive checks for undefined. Inconsistent documents that nobody gets around to migrating. A type system that says field?: string when what it really means is “this might be the old shape — we never finished updating everything.” Every new feature ships a little slower because you have to keep inferring the real schema from the union of everything you’ve seen so far.
In principle, a single shared TypeScript type per document could enforce consistency. In practice, in any codebase with more than one developer, it drifts — the backend has its version, the frontend has a slightly different one, someone adds a field and forgets the shared type. What I’ve seen repeatedly in larger codebases is the defensive collapse: every field marked optional, not because the data is actually optional but because nobody can prove what’s really in the store anymore. You end up guarding against undefined everywhere, including for fields that are, in fact, always present.
What agents changed
Writing a proper migration means:
- Authoring the SQL
- Updating every place in the code that reads or writes the affected columns
- Adjusting the types
- Running it against a shadow database
- Writing the backfill for existing rows
- Testing it end-to-end
That list is why we used to avoid migrations and, by extension, SQL altogether. Schema-less storage is a legitimate tool for genuinely unstructured payloads, logs, event streams, and data where a schema would be a lie. But a lot of us reached for it on problems it wasn’t built for: well-defined backend data that just happened to be changing shape fast. The attraction wasn’t the schema-less storage itself — it was avoiding the cost of keeping a relational schema in sync with fast-moving application code.
That list is also exactly the shape of work agents are good at. The SQL itself is the smallest piece. The downstream fanout — reading every call site, updating every type signature, catching the subtle places where a column change breaks an unrelated feature — is mechanical, tedious, attention-demanding, and perfectly bounded. If I hand Claude Code a clear change (“add these 10 columns to executive_orders, update the enrichment worker to write them, update the API response type”), the work I used to dread is done in minutes with minimal oversight on my part.
Oval Brief, by the numbers
So what does that actually look like at project scale?
Oval Brief runs on Neon (serverless Postgres) behind Cloudflare Workers, with Drizzle as the ORM. Across the 34 migrations in the 5-week run to release:
- A handful were additive — one of them added 10 LLM-output columns in a single round, plus partial indexes on two of them.
- Several were structural — including extracting the
presidentslookup out of a JSONB field onexecutive_orders, backfilling the foreign key from the old JSON path, and dropping the original column. Not trivial. The kind of migration a team would schedule a meeting about. - A few were data reshapes — splitting a single
reasoningcolumn intoexplanation(user-facing,NOT NULL) andllm_notes(internal), accepting the data loss, and letting the type system find every call site that needed updating.
Eleven tables now, four Postgres enums, an HNSW vector index for semantic search, and a few expression-based unique constraints the ORM can’t fully model. Almost none of this was planned up front — it showed up as the product shape clarified.
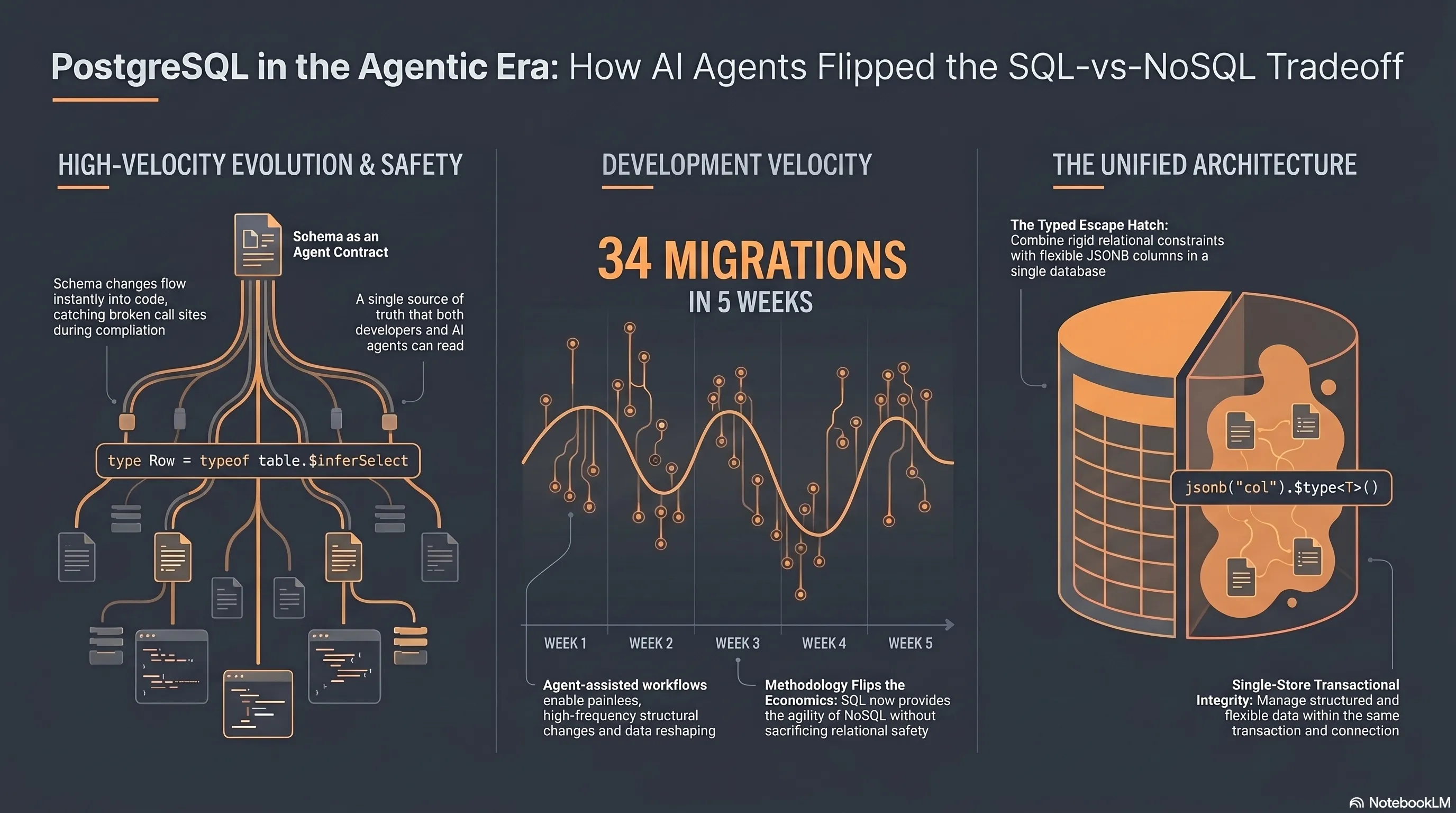
The schema is now a contract that the agent reads too
A Drizzle schema is a single TypeScript file. One source of truth for what tables exist, what columns they have, and what types and constraints apply. If I point an agent at that file, it knows the system, and it can write a migration that doesn’t conflict with an existing unique constraint. It can update a downstream query and trust that ExecutiveOrderRow reflects reality.
A Firestore collection isn’t like that. The only way to know what a document “really” looks like is to read enough of them to infer the union of shapes. An agent can work with Firestore, obviously, but it’s always working with partial information until it has seen the old and new versions of every document. The type definitions in the code are aspirational, not enforced.
And the type system does more work than it used to. On Oval Brief, every table exports two types derived from the Drizzle schema — ExecutiveOrderRow for reads, NewExecutiveOrder for writes. When migration 0008 added those 10 columns, every consumer of those types picked up the new shape on the next typecheck. When migration 0015 renamed reasoning to explanation, every insert site broke at the type checker with “property reasoning does not exist.” The compiler finds every one of them automatically.
I used to think of compile-time type safety as something I owed future-me. Now it’s how I hand work to an agent: the stricter the schema, the cleaner the handoff.
The JSONB clincher
There’s still an honest argument for a schema-less store: some payloads genuinely don’t have a shape, or their shape is someone else’s problem. Think of log entries, webhook payloads from an API you don’t control, or LLM responses you want to archive raw.
Postgres has an answer for that, and it’s the part that makes this specifically a PostgreSQL moment rather than a “SQL in general” moment.
JSONB columns let you store unstructured payloads in a relational database, with type checking at the application layer. On Oval Brief, executive_orders.raw_json is declared:
jsonb("raw_json").notNull().$type<FederalRegisterDocument>()The Zod schema that validates the Federal Register API response at ingest produces a type. That’s the type the JSONB column reads back as. The database doesn’t enforce the shape because the ingest boundary did. The relational columns inherit the full weight of Postgres constraints; the blob columns gain the flexibility of a document store within the same database.
That’s what kills the last argument for going NoSQL for the entire data store. You get a typed relational core where you want one, and a typed JSON escape hatch where you don’t.
So what really changed
The problem hasn’t changed. Startups still need to iterate fast on their data models and ship products before the schema stabilizes.
NoSQL solved a real problem in 2020. The dev-loop cost of evolving a relational schema was genuinely painful, and document stores removed it. Picking Firestore was the right call for what we were building.
What changed is the human effort involved. Agents have made the expensive part of SQL cheap. And once you’re not paying for migrations in human hours, the tradeoff stops making sense. Now we can have schema safety, plus a type-system handoff to agents — a way of working that didn’t exist as a concept six years ago — and JSONB as the escape hatch for the cases that really are unstructured.
That’s what this moment is really about: a tradeoff that reversed quietly, almost as a side effect of the agentic era.